FAQs on: General
The Weekly Schedule Page presents all you need to know in chronological order (for each week) while the other pages have some of the same content organized by topic.
The Weekly Schedule Page is the one page you need to refer weekly. Although there is a lot of content in the Admin Info page and the Textbook page -- which you are welcome to read in those respective pages -- the same content is also cross-embedded in the corresponding weekly schedule pages. Such cross-embedded extracts usually appear in expandable panels and can be identified by the symbol in the panel title.
In CS2113, A+ is not given simply based on the final score. To get an A+ you should,
- score enough to be close to the higher end of the
Agrade band. - be considered technically competent by peers and tutor (based on peer evaluations and tutor observations).
- be considered helpful by peers (based on peer evaluations and tutor observations).
- In particular, you are encouraged to be active on the forum and give your inputs to ongoing discussions so that other students can benefit from your relatively higher expertise that makes you deserve an A+.
- Whenever you can, go out of your way to review pull requests created by other team members.

Sometimes, small things matter in big ways. e.g., all other things being equal, a job may be offered to the candidate who has the neater looking CV although both have the same qualifications. This may be unfair, but that's how the world works. Students forget this harsh reality when they are in the protected environment of the school and tend to get sloppy with their work habits. That is why we reward all positive behavior, even small ones (e.g., following precise submission instructions, arriving on time etc.).
But unlike the real world, we are forgiving. That is why you can still earn full marks for participation even if you miss a few things here and there.
Defining your own unique project is more fun.
But, wider scope → more diverse projects → harder for us to go deep into your project. The collective know-how we (i.e., students and the teaching team) have built up about SE issues related to the project become shallow and stretched too thinly. It also affects fairness of grading.

That is why a strictly-defined project is more suitable for a first course in SE that focuses on nuts-and-bolts of SE. After learning those fundamentals, in higher level project courses you can focus more on the creative side of software projects without being dragged down by nuts-and-bolts SE issues (because you already know how to deal with them). However, we would like to allow some room for creativity too. That is why we let you build products that are slight variations of a given theme.
Also note: The freedom to do 'anything' is not a necessary condition for creativity. Do not mistake being different for being creative. In fact, the more constrained you are, the more you need creativity to stand out.
We have chosen a basic set of tools after considering ease of learning, availability, typical-ness, popularity, migration path to other tools, etc. There are many reasons for limiting your choices:
Pedagogical reasons:
- Sometimes 'good enough', not necessarily the best, tools are a better fit for beginners: Most bleeding edge, most specialized, or most sophisticated tools are not suitable for a beginner course. After mastering our toolset, you will find it easy to upgrade to such high-end tools by yourself. We do expect you to eventually (after this course) migrate to better tools and, having learned more than one tool, to attain a more general understanding about a family of tools.
- We want you to learn to thrive under given conditions: As a professional Software Engineer, you must learn to be productive in any given tool environment, rather than insist on using your preferred tools. It is usually in small companies doing less important work that you get to chose your own toolset. Bigger companies working on mature products often impose some choices on developers, such as the project management tool, code repository, IDE, language etc. For example, Google used SVN as their revision control software until very recently, long after SVN fell out of popularity among developers. Sometimes this is due to cost reasons (tool licensing cost), and sometimes due to legacy reasons (because the tool is already entrenched in their codebase). While programming in school is often a solo sport, programming in the industry is a team sport. As we are training you to become professional software engineers, it is important to get over the psychological hurdle of needing to satisfy individual preferences and get used to making the best of a given environment.
Practical reasons:
- Some of the topics are tightly coupled to tools. Allowing more tools means tutors need to learn more tools, which increases their workload.
- We provide learning resources for tools. e.g., 'Git guides'. Allowing more tools means we need to produce more resources.
- When all students use the same tool, the collective expertise of the tool is more, increasing the opportunities for you to learn from each others.
Meanwhile, feel free to share with peers your experience of using other tools.
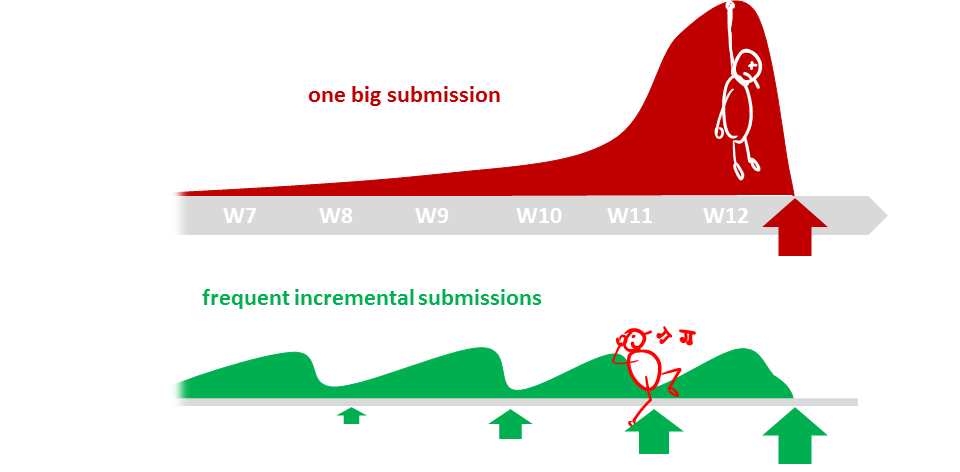
The high number of submissions is not meant to increase workload but to spread it across the semester. Learning theory and applying them should be done in parallel to maximize the learning effect. That can happen only if we spread theory and 'application of theory' (i.e., project work) evenly across the semester.
In addition, spreading the work across the semester aligns with the technique that we apply in this course to increase your retention of concepts learned.
While we are aware that Java 21 is a more recent version of Java, we are sticking with Java 17 for the time being. We plan to move to Java 21 in a future semester when its adoption is sufficiently high.
Related: The industry is slow to move to new Java versions. It is likely the legacy Java systems you'll encounter in your internships/jobs are even older than Java 17.
FAQs on: Participation
In most quizzes, answers will be released within a day after the quiz deadline.
On a related note, if you are not confident about the answer you've selected for a question, you are welcome to discuss it in the forum, even if the submission deadline is not over yet (but one question per thread please).
See the panel below:
Admin Policies → Absences due to valid reasons
- a)An occasional absence or two will not affect your marks, as the marking scheme already has built-in buffers to absorb such occasional absences/lapses. If you miss a lecture/tutorial/task for a valid reason (e.g., MC, LOA, official university event, officially representing NUS in a competition), just do your best to catch up.
- b)Let us know only if you failed to earn full marks for participation due to such a reason (or if you feel you are at risk of not earning full marks), in which case we will consider giving an alternative avenue to earn marks missed due to the absences.
Detail of participation marks calculation is here. - c)Normally, there is no need to inform us (e.g., the tutor) of such absences or the reason, although you are welcome to.
No need to send us your MC (it is best not to share your health information with others, unless necessary), but keep a copy of it safely, in case we ask for it later, in relation to (b) given above.
FAQs on: iP
Adding a git tag in the iP is a self-declaration that you think you are done with the iP increment. We take your word for it. We don't check the code to see if you have actually done the said increment. Therefore, it is just a mechanism for you to self-declare progress and for us to monitor those progress declarations.
Go ahead and fix it in a subsequent commit. There is no need to update the previous commit or move the corresponding tag to the new commit. As we do not test your code at every tag, earlier bugs will not affect your grade as long as they are fixed eventually. Similarly, feel free to improve the code of previous increments later.
It's fine. Be more careful in the future. Your iP marks will not be affected for missing an occasional deliverable such as this one.
If you still want to make that branch-___ item green in the iP dashboard, you can simply create a branch with the required branch name, do some commits in it, and merge it to master. The dashboard will accept it as long as it has the right name and merged to the master branch.
When something is not covered by the given standard/convention, you are free to choose which style you want to follow for that, but try to be consistent with the existing code (if any), and ensure everyone in the team follows the same (if it is a team project).
In some areas, the sample Checkstyle rules file (recommended by the SE-EDU guide) may be slightly more permissive/restrictive than (but not contradictory to) the given Java coding standard. You are free to tweak the Checkstyle file if you wish. It is fine as long as your code is compliant with the given coding standard.
Deciding a feature’s behavior is a product design decision, and this is a good opportunity to practice that aspect of software engineering. So, decide for yourself: as a user of this product, what is the minimally acceptable behavior of this feature?
Yes, you will get a chance for resubmission, without any penalty.
That said, a resubmission is likely to be held to a higher bar than the standard bar for iP. So, it is in your interest to ensure your initial iP submission meets the bar for full marks.
There is no need to ask for extensions to the iP final submission deadline.
It is ideal if you finish the iP by original deadline, but if you could not finish it by that deadline, we'll be giving you an automatic 3-day deadline extension. Further deadline extensions beyond that might be possible too, provided we see evidence of you trying to progress in the previous deadline extension (and not simply postponing work to take advantage of the deadline extensions).
- While there will be no penalty for such a deadline extension, keep in mind that the longer you take to finish the iP, the less time you'll have for the tP.
- To reiterate, the said deadline extension will be given automatically, after the initial deadline is over: Please don't send us deadline extension requests in advance.
- Caution: Unlike the iP, no free extensions will be available for the tP final submission deadline. Even a one-second delay will be considered a late submission and will have to be penalized, as deadline compliance is a learning outcome of the course.
FAQs on: Tutorials
TLDR: In this course, tutor's main job is to deliver tutorials. Hence, tutors can answer questions related to (and arising from) the tutorial delivery. But they are not allowed to answer admin questions. They are not allowed to help with technical issues.
- Good I did not understand your explanation of that question. Why did you say "a b c"?
Reason: This question is a follow-up from a tutorial discussion. - Good This is how I understood coupling. Is that correct?
Reason: This question shows you have put in some effort to learn the topic and seeking further clarification from the tutor. - Bad What is coupling? | What is SLAP?
Reason: These are concept covered in the textbook and other resources provided.
The course has MANY admin details and there are subtle changes from semester to semester. Tutors might not be aware of those changes, increasing the risk that you receive subtly incorrect answers. Besides, it is not fair to expect tutors to know all the admin details, as they should be using their memory for things related to their own courses.
Tutors are not allowed to give ad hoc feedback on yet-to-be-graded components (e.g., iP or tP components, which accounts for a very high percentage of the overall grade),
- to ensure the work you submit for grading is entirely your own (for the same reasons why you are not allowed to ask invigilators for 'feedback' on your answers while you are answering the final exam paper).
- to ensure fairness across teams (because if tutors were allowed to give feedback on their own, it will be impossible to ensure all tutors give the same level of feedback).
It is true that the teaching team will not give ad hoc feedback on yet-to-be-graded project deliverables. But you will receive systematic feedback at various points of the project, in a way that ensures all of you receive the same level of feedback about same things.
More importantly, we aim to develop your thus reducing your reliance on someone else's feedback to decide how to improve. To this end, we have set up various learning tasks to help you judge your own work. Examples:
- Tutorial tasks that go through a 'sample' project aspect/artifact (e.g., use cases of a sample project) and find problems in it. This way, we can ensure that all of you encounter all the important learning points related to that aspect/artifact, even if some may not be relevant to your own project (which means you wouldn't have encountered them on your own).
- Peer evaluations of each other's work, within teams and between teams. This gives you a way to exercise your evaluative judgement skills.
The pedagogical reason: Learning how to solve technical problems, and /give/receive help, are learning outcomes of this course, and are critical skills for software engineers. So, we want you to practice those things in this course as much as possible.
A practical reason: Unlike in lower-level programming courses, the technical problem you encounter in this course are varied and dependent on your OS and tool choices. It is not possible for one person (e.g., your tutor) to know how to help with problems related to all OS'es and all tools used by students under his/her care. It is more practical to troubleshoot such problems via the course forum, as that gives you a way to get help from all your peers in the class, the entire teaching team, and a group of past students who have volunteered to help current students solve technical problems. Based on past data, we know that more than 90% of the problems posted in the course forum get resolved within 24 hours. So, by not allowing you to get tech help from tutors, we are directing you to a more effective way to resolve those issues, while learning valuable skills at the same time.
Our tutorial participation bar has enough of a buffer to allow an occasional absence (irrespective of the reason for absence). While we are not able to make special arrangements for absences due to reasons not accepted as valid by NUS (e.g., due to family event, interview, travel delays, overslept etc.), such absences are unlikely to affect your participation marks unless frequent.
- You are welcome to keep your tutor informed of such absences as a courtesy, but it is not a requirement.
- If you miss a tutorial, do try to catch up as best as you can .
- If you wish to attend a different tutorial timeslot in a specific week, please send your request to the course email (
cs2113@comp.nus.edu.sg).
In the past, many students have requested to increase the tutorial duration because a mere hour is barely enough to get through all the tutorial tasks. Increasing the tutorial time is not possible due to lack of venues and tutors. Instead, let's try to make the best of the one hour available by coming well-prepared and starting on time. Note that the better prepared you are, the higher the chance of completing all activities allocated to a tutorial within time.
There are several reasons:
- NUS policy requires all small classes to be F2F. Physical interaction with peers is an essential part of the university experience.
- While Zoom is more convenient, they are not as effective in achieving some learning outcomes. For example, we are training you for working in team projects, and in technical communications, both of which sometimes need to be done in the F2F mode.
- Your physical presence allows the tutor to observe team dynamics better. To give an example, sometimes even a team's seating positions can tell us the level of team cohesion.
Note that we do track your arrival time, as late arrivals hinder your ability to participate in the tutorial fully.
If you anticipate a late arrival due to a reason beyond your control (e.g., due to the previous class ending late), here are some strategies to mitigate the impact:
- Prepare for the tutorial tasks in advance, especially the first one. This will allow you to complete the task in time even if you arrive a few minutes late.
- Join the Zoom meeting while you are on the way to the class.
Not to worry; there is no penalty.
We download the workspace file at 10-minutes mark to discourage students from continuing task 1 (which is just a warmup activity) even after task 2 has started, thus not getting the full value of task 2 (which is more important than task 1).
We do use the downloaded workspace files to identify students who consistently come prepared for tutorials and do a good job in tutorial tasks (e.g., when selecting tutors), but we do not penalise students based on those workspace files.
If you frequently find yourself being unable to finish task 1 in time, you can consider doing it in advance.
FAQs on: UML
UML is not used very frequently by practitioners. In particular, most would not bother to draw detailed UML diagrams before (or in parallel to) coding.
UML diagrams can still provide practical value in some situations e.g., when documenting internal design details, when discussing design alternatives. However, even when using UML is beneficial, some may avoid using it due to lack of proficiency. In fact an average programmer is likely to be able to survive without drawing any UML diagrams, and only occasionally having to interpret UML diagrams drawn by others.
However, being able to communicate about code/design without referring to actual code is an essential skill, as the code is not always available (e.g., it may not exist yet or the codebase may be too big for to be used for such communications). While in some cases we can use ad hoc notations (simple boxes, arrows, labels) for such communications, using a standard modeling notation can make such communications universally understood. UML is the leading general-purpose notation used for modelling software design. It can be used for basic modelling irrespective of the domain of the software project. For more intense modeling needs, we can go for a domain-specific modelling notation e.g., Business Process Model and Notation (BPMN).
Besides, UML is just a tool that we use to learn a more fundamental SE skill: the ability to model code visually, especially at higher abstraction levels. This skill is necessary to be able to build mental models of large code bases in our head, even if you don't actually draw physical diagrams, UML or otherwise.
It is true that we are 'overdoing' UML a bit in this course. Because UML is not used frequently in the industry (especially, by junior developers), you will not have many chances to learn it 'on the job' in the early part of your career. Hence, we try to ensure you learn UML well-enough to be able to use it a few years later, even if you don't get to use it in the interim period.
Here are some options you can consider:
- Use the closest matching notation, and use UML notes to provide the missing information.
- Use an alternative means to communicate (e.g., pseudocode, or even actual code), instead of using a UML diagram.
- Leave out the complex part from the diagram, or give a simpler view in the model, if the complex part is not really relevant to the purpose of the diagram (but also mention that the model is a simplified view).
Caution: For course deliverables, it is best not to use UML notations not covered in the course.
There are several reasons:
- Some design concepts do not have direct translations to a mechanism in the programming language e.g., most programming languages do not have a direct way to implement a bidirectional association.
- Some programming language constructs might not have corresponding UML constructs e.g., lambdas
- Some implementations can choose to deviate from the intended design due to other valid reasons such as performance, code clarity, convenience etc.
In a real project, in most cases, the person drawing the diagram is likely to be the same person who wrote the code, which means that person is likely to know the intended design already. If this is not the case, one can try to approximate the intended design based on one's own domain knowledge, consulting domain experts, from other sources such as project documentation (and code comments).
In an exam question, the missing info will be provided as part of the question, if it is relevant to the expected answer.
FAQs on: tP
Given below is the relevant section from Appendix F: Handling Team Issues:
Problem: A team member is MIA from the start, or for an extended period of time.
Guidance for the team: It is not your responsibility to ensure a member keeps in touch with the team or/and keeps pace with the project. So, after one or two attempts to get in touch with the MIA member, proceed with the project without the missing member, but keep that member in the loop (e.g., CC all team communications to that member).
Also inform the teaching team about the MIA member.
If the member was previously allocated some future project tasks, redistribute those tasks, and adapt project targets accordingly (i.e., reduce targets because now you are operating with one fewer member).
If the missing member reappears later (by which time you may have redistributed the work to other members), there is no need to disrupt your current plan. Instead, you can suggest (or let the person figure out) ways to contribute without affecting the current project plan. For example, the person can add an additional nice-to-have feature that will not require changes to other features.
Guidance for the member: If you need to be MIA for a period of time, inform the team when you hope to be back in action. You are welcome to, but not required to, inform the team the reason for the absence (as this may be personal).
- It is an opportunity to exercise your product design skills because optimizing the product to a very specific target user requires good product design skills.
- It minimizes the overlap between features of different teams which can cause plagiarism issues. Furthermore, higher the number of other teams having the same features, less impressive your work becomes especially if others have done a better job of implementing that feature.
The size of the target market is not a grading criterion. You can make it as narrow as you want. Even a single user target market is fine as long as you can define that single user in a way others can understand (reason: project evaluators need to evaluate the project from the point of view of the target users).
In that case, at a later stage, you can add more user stories until there is enough for a meaningful work distribution. But at this point focus on selecting the smallest sub-set of must_have user stories only.
Generally, not recommended. It can be allowed only if the application provides an easy way to decrypt the file, and encrypt it again after editing it manually.
Followup question: What if the data in the file is confidential, and therefore, it is risky to leave it in plaintext format?
While this is a valid concern, you can assume/require that the app is used in a secure environment in which data are protected by default e.g., a personal computer already password protected.
It is OK (i.e., no penalty) if you overshoot the deadline in initial iterations. Adjust subsequent iterations so that you can meet the deadline consistently (which is an important learning outcome of the tP) by the time you reach the end of the tP.
Yes (an example), although having too many non-coding tasks in the issue tracker can make it cluttered.
GitHub Issues does not have a direct way of doing this. However, you can use a task list in the issue description to indicate sub-tasks and corresponding issues/PRs -- (an example)
You can use this recently-added GitHub feature to mark an issue as a sub-task of another issue.
This is discouraged in the tP, as it makes task allocations (and accountability) harder to track.
Instead, shared tasks can be split into separate issues. For example, instead of creating an issue Update teams page with own info and assigning it to all team members (in which case, this issue can't be closed until all members do their part), you can create issues such as Update teams page with John's info that can be assigned to individual members.
A: In the tP (in which our grading scripts track issues assigned to each member), it is better to create separate issues so that each person's work can be tracked separately. For example, suppose everyone is expected to update the User Guide (UG). You can create separate issues based on which part of the UG will be updated by which person e.g., List-related UG updates (assigned to John), Delete-related UG updates (assigned to Alice), and so on.
This is encouraged, while not a strict rule. Creating an issue indicates 'a task to be done', while a PR is 'a task being done'. These are not the same, and there can be a significant time gap between the two.
Furthermore, posting an issue in advance allows the team to,
- anticipate a PR is coming
- discuss more about the task (in the issue thread) e.g., alternatives, priority
- indicate who will be doing the task (by adding an assignee), when it should be done (by adding it to a milestone)
Course admin perspective: It's up to you. We do not directly enforce any requirement on this. How well you do this can affect your grade indirectly though e.g., if PR reviews are weak, low quality code could get merged, which can in turn affect grading for code quality and bugs in the product. If you 'overdo' PR reviews, you'll waste time/effort and slow down the progress, which can affect marks as well.
Teaching/learning perspective: Learning to optimize the process is an intended learning outcome. You can do this iteratively. That is, the team can decide your own policy/process, and tweak it as you go. For example, you can decide to have a minimum of n reviews at rigor level X for each PR. After doing that for a while, you can evaluate how it is working, and tweak if necessary (reduce n or lower X if you feel like it is slowing down the project too much without helping to increase quality that much | increase n or set a higher X if you think the code being merged is below-par quality).
SE perspective: This depends on many things, such as target quality (higher target quality requires high rigor PR reviews), availability of reviewers, level of other quality assurance mechanisms in place (e.g., automated checks done on the code, such as Checkstyle). Might even vary based on type of PR (some PRs need closer scrutiny than others).
Should reviewer run the code locally to ensure the code works? This also depends on if (and how well) the work in the PR is covered by automated tests run by the CI.
Most long-running projects in real world will establish their own policies/norms, either written down formally or passed down informally (i.e., new devs follow what current devs do).
While this multistep-command approach (i.e., giving the user a series of prompts to enter various data elements required to perform an action) has its benefits (e.g., no need to memorize the command format), a deeper look reveals why the one-shot-command approach is better.
Before delving any further, note how leading CLI-centric software such as Git and Linux don't use the multistep approach either. Why?
The multistep approach basically results in a 'text-based GUI simulation' that is harder to use than an actual GUI (obviously), whereas a well-designed CLI in an expert's hands can perform tasks faster than an equivalent GUI (which is what we are going for). A person good at typing and remembers the command can type a command faster than a user going through a type-read-type-read sequence required by the multistep-command. Now imagine user made a mistake in the response to an earlier prompt -- correcting that would take a lot more work.
That being said, multistep commands can complement the one-shot-command approach in specific cases e.g.,
- as a crutch for new users to learn the command format
- to be used for rarely-used tasks or tasks requiring multiple steps (e.g., importing data from a file)
This round is for your info only (i.e., no direct impact on grades). After the final tP peer evaluation session (which is done at the end of the semester, and can affect the tP grading) results are published, you will get a chance to submit your objections if you don't agree with the evaluations you received.
eceiving 'lower than expected' feedback early is a good thing; it shows in which areas your team members are less-happy about your contribution/conduct, while there is still time to take corrective actions. It is much worse when team members give good ratings about aspects they are unhappy about, just to avoid conflict, and hold back the negative feedback until the project is over -- in such cases you will be taken by surprise (hey! I thought everything was fine!!) with no time left to rectify the problem.
The DG is primarily meant to help current/future developers. In general, the DG is expected to provide minimal yet sufficient guidance for developers, serving them in the following ways:
- It act as a starting point for developers, before they can dive into the code itself e.g., by providing an architecture-level overview of the system
- It provides a roadmap to developers e.g., pointing out where important information can be found in the code
- It complements the code, providing info/perspectives not specified in the code (e.g., rationale for high-level design choices, details of dev ops)
or not easy to grasp from the code (e.g., architecture level view, visual models).
Therefore, decide based on how the inclusion/exclusion affects that target audience (you belong to the target audience too!) in achieving the above objectives.
Not a good idea. Given below are three reasons each of which can be reported by evaluators as 'bugs' in your diagrams, costing you marks:
- They often don't follow the standard UML notation (e.g., they add extra icons).
- They tend to include every little detail whereas we want to limit UML diagrams to important details only, to improve readability.
- Diagrams reverse-engineered by an IDE might not represent the actual design as some design concepts cannot be deterministically identified from the code e.g., differentiating between multiplicities
0..1vs1, composition vs aggregation.
Not surprisingly, a common question tutors receive is "can you look at our project and tell us if we have done enough to get full marks?". Here's the answer to that question:
The tP effort is graded primarily based on peer judgements (tutor judgements are used too). That means you will be judging the effort of another team later, which also means you should be able to make a similar judgement for your own project now. While we understand effort estimating is hard for software projects, it is an essential SE skill, and we must practice it when we can.
The expected minimum bar to get full marks for effort is given here.
If you surpass the above bars (in your own estimation), you should be in a good position to receive full marks for the effort. But keep in mind that there are many other components in the tP grading, not just the effort.
Not necessarily. Choose based on importance.
In any project, there are always things that can be done 'if there was more time'. If fixing a certain bug has low impact on users, and fixing it is not as important as the work done (or intend to do in the current iteration), you can justify not fixing it with the reason 'not in scope' of the current iteration.
Similarly, a missing feature enhancement can be justified as 'not in scope' if implementing that could have taken resources away from other important project tasks.
Bugs and possible enhancements 'not in scope' will not be penalized.
Here are some reasons:
- We want you to take at least two passes at documenting the project so that you can learn how to evolve the documentation along with the code (which requires additional considerations, when compared to documenting the project only once).
- It is better to get used to the documentation tool chain early, to avoid unexpected problems near the final submission deadline.
- It allows receiving early self/peer/instructor feedback.
In terms of effort distribution, it's up to the team to tell us who did how much. Same goes for assigning bugs. So, it's fine for someone to take over a feature if the team is able to estimate the effort of each member, and they have a consensus on who will be responsible for bugs in that feature.
For code authorship, only one person can claim authorship of a line, and that person will be graded for the code quality of that line. By default, that will be the last person who edited it (as per Git data) but you can override that behavior using @@author tags.
Product design is hard (harder than programming). Feature design choices (e.g., to support sorting or not support sorting, sort descending or ascending, which sort order should be default, etc.) are subjective and is case-by-case.
General guidance: Choose by considering
[A] what is best for the user (specifically, with reference to the target user profile you chose for the product), but also factor in
[B] what is possible within your resources (e.g., time, manpower, expertise) -- what is 'ideal' may not be practical.
Implications for the practical exam (PE):
Keeping in mind that during the PE testers can file bug reports against design choices, whatever choice you make, be prepared to justify your choice (based in [A] and [B] above) in case a tester filed a bug report objecting to the current design.
Given these justifications are subjective, if both the developer's justification and the tester's justification seems to be equally valid, we will rule in favor of the developer (i.e., no penalty for the developer).
However, if the dev team went with an inferior choice while another superior choice could have been taken using roughly the same amount of resources, the current design choice is flawed. For example, if 'sorting items in ascending order by default' is clearly the better choice, but the dev team chose descending order to be the default, assuming implementing either order takes roughly the same amount of resources, the dev team's design choice is flawed.
FAQs on: tP Troubleshooting
It is possible that the master branch has received new commits after your PR passed CI the last time. So, if GitHub indicates that your PR is not up-to-date with the latest master branch, synchronize your PR branch with the master branch (which will run the CI again) before merging it.
First, check which OS it is failing in. Some behaviors can be OS-dependent. For example, file paths are case-insensitive in Windows but not in Unix/Mac.
Second, note that PR CI does a temporary merge of master branch to the PR branch before running tests, to verify if the checks will pass after you merge this PR. So, if the master branch has progressed after you started your PR branch, those new commits can affect the CI result. The remedy is to pull the master branch to your repo, merge it to your PR branch, and run tests again (which should fail as well, but you can now find the reason for the failure and fix it).
FAQs on: tP PE
The product testing part of the PE (and the PE-D) is expected to take no more than 2 hours. Typically, the bugs you can find within 2 hours should be enough to get full marks for the product testing component of the tP. The additional time is given as a buffer, and to reduce stress.
Note that you can send no more than 6 bugs to the dev team anyway, and the product testing is only a small component of tP marks (i.e., 3-4 marks). So, there is not much value spending too long on this.
Given the nature of the product you are testing (small, simple), we expect that everyone will be able to find enough bugs to qualify for full marks for the product testing portion of the tP, even if you are not using any tools at all (i.e., manual testing only). At this scale, and at the current state of the art, we estimate the difference between using AI tools and manual testing to be negligible.
Yes, you may. Given that the dev team did not get to see this additional info when they triaged the bug, the weight such additional info adds to your case is lower than if you had that info in the initial bug report. Nevertheless, it can still help your cause, especially if the dev team should have thought about that info on their own, even if they were missing in the initial bug report.
As each product is tested by 4-5 testers, after all PE bugs have been finalized, we know how 'buggy' each product is. We then use that information for calculating your PE-related marks. So, the marks are calibrated to match the bugginess of the product you tested.
No. Given the PE has only a short time, we don't expect you to find all bugs in the product. To get full marks, you only need to report a certain percentage of the bugs (e.g., half), or a certain quantity of bugs (the quantity also factors in the nature of the bug e.g., severity), whichever is lower.
Penalty for bugs is applied based on bug density, not bug count. Here's an example:
nbugs found in Ann's feature; it is a big feature consisting of a lot of code → marks for dev testing: 4nbugs found in Jim's feature; it is a small feature with a small amount of code → marks for dev testing: 1
Although both had the same number of bugs, as Ann's work has a lower bug density than Jim's, she earns more marks for the dev testing aspect.
Yes, you may. Given that the dev team did not get to see this additional info when they triaged the bug, the weight such additional info adds to your case is lower than if you had that info in the initial bug report. Nevertheless, it can still help your cause, especially if the dev team should have thought about that info on their own, even if they were missing in the initial bug report.
FAQs on: Exam
You are welcome to try past exam papers available in the library and post answers in the forum to discuss with others. The teaching team will contribute to those discussions as well, and ensure you reach a reasonable answer.
Caution: The scope of the course and the exam format evolve over time and some past questions may not be exactly in sync with the current semester. The format of the archived exam papers is different from the current format.
The standard operation procedure for digital exams: Some venues have charging points within reach of every seat. If that's not the case, you will be moved to another location with a charging point when your laptop power level reaches a low level. Pre-allocating you a seat with a charging point is not feasible, as the number of such requests can easily exceed the number of charging points in the venue.
Reasons:
- To minimize opportunities for collusion or over-the-shoulder copying from others (the risk of the latter is higher in this type of exam due to the upright exam device screens being easily visible to other exam takers).
- Not unreasonable for the materials tested, nature of the questions, and the proficiency level expected -- i.e., when using this knowledge in a real life SE project discussion, it will be rare for you to go back to revise what you said earlier in the discussion, nor will you be able to 'answer the easy questions first and come back to harder questions later'.
Note that you are allowed to go back and modify diagrams you drew in part 1, just like in a real life project scenario.
Not to worry; we understand that this restriction can make the exam feel 'harder' than otherwise. We have the following measures to compensate:
- There is a buffer of two extra questions, to cushion the impact of making a mistake in question, realizing it later, and not being able to go back to fix it.
- There is a buffer of six extra minutes (on top of the two extra questions), to cushion the impact of needing to spend extra time on a question to ensure the answer is correct before moving to the next question.
- The question difficulty is calibrated to match this mode of testing i.e., the questions are easy enough that can be done one shot in a short time.
- Our tutorials prepare you for this mode of testing (provided you do them sincerely), as our tutorials get you to answer a series of small MCQ-like questions and short-answer questions.